What are the major text analytics models used in CX Monitoring?

Text analytics models have become an invaluable tool in the field of business intelligence. By analyzing text data, these models can provide valuable insights into customer sentiment, product performance, and much more. They can help organizations gain a deeper understanding of customer behavior, trends, and preferences, which can help shape and inform their business decisions. Transmonqa’s Quality monitoring tools in India are increasingly being used for marketing purposes, to better understand customer preferences and target the right audiences with the right messages. With the power of automated call monitoring and call monitoring software, businesses can gain a better understanding of their customers and use that information to drive better decisions and increase sales.
What are the 4 types of text analytics models?
Many statistical models can be used for text analytics in customer service, and the best model for a given situation will depend on the specific goals and needs of the business.
Here are a few popular models that are commonly used in text analytics for Customer Service:
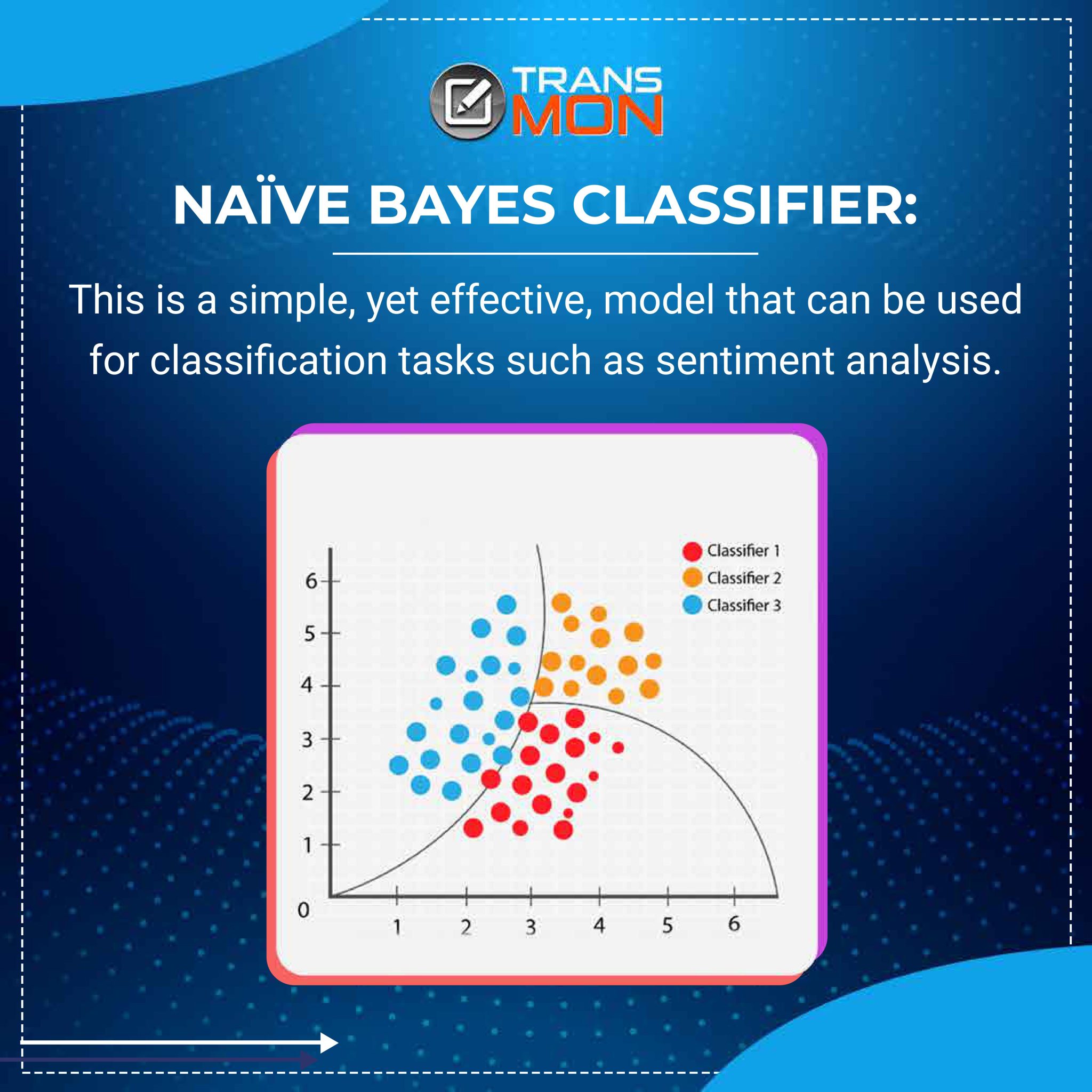
- Naïve Bayes classifier:This is a simple, yet effective, model that can be used for classification tasks such as sentiment analysis.
- Support vector machines (SVMs):These are powerful models that can be used for classification and regression tasks.
- Latent Dirichlet allocation (LDA):This is a probabilistic model that can be used for topic modeling, which involves identifying the main topics discussed in a set of documents.
- Word embedding models: These are models that represent words in a continuous vector space, which can be used for tasks such as document classification and sentiment analysis.
Ultimately, the best model for a given situation will depend on the specific goals of the business, the amount and quality of data available, and the resources and expertise of the team. It may be necessary to experiment with different models and evaluate their performance to determine the most effective one for a particular task.
1. What is the Naive Bayes classifier?
The Naive Bayes classifier is a statistical model that is commonly used in text analytics and natural language processing (NLP). It is based on the idea of using Bayes’ theorem, which is a way of calculating the probability of an event based on prior knowledge of conditions that might be related to the event.
In the context of text analytics, the Naive Bayes classifier is often used for classification tasks, such as determining the sentiment (positive, negative, or neutral) of a piece of text. It works by using a set of training data to build a model that can predict the class (e.g., positive or negative sentiment) of a given piece of text based on the presence of certain words or phrases.
One of the advantages of the Naive Bayes classifier is that it is simple and easy to implement, and it can often achieve good results with relatively little data. However, it does have some limitations, such as its assumption that the features (e.g., individual words or phrases) in the data are independent of one another, which is not always the case in natural language text. Despite this, the Naive Bayes classifier is still a widely used and effective tool in text analytics.
Uses of Naive Bayes classifier
Here is an example of how the Naive Bayes classifier could be used in customer service:
Imagine that a company wants to use text analytics to automatically classify customer reviews as positive or negative. The company has a dataset of customer reviews that have been labeled as either positive or negative by human auditors. The company can use this labeled dataset to train a Naive Bayes classifier model.
Once the model is trained, it can then be used to predict the sentiment of new, unseen customer reviews.
For example, if a customer writes a review that says, “I am extremely satisfied with the service I received from your company. The staff was friendly and helpful, and the product exceeded my expectations,” the model would likely classify this review as positive.
On the other hand, if a customer writes a review that says, “I am extremely disappointed with the service I received from your company. The staff was rude and unhelpful, and the product did not meet my expectations,” the model would likely classify this review as negative.
By using the Naive Bayes classifier to classify customer reviews, the company can quickly and automatically identify positive and negative feedback, which can help them to improve their products and services and address customer concerns.

2. Support Vector Machines (SVMS)
The primary use of the Support Vector Machine (SVM) algorithm is for classification purposes in machine learning. Its objective is to identify the optimal line or decision boundary that divides an n-dimensional space into classes so that future data points can be accurately sorted. This optimal boundary is referred to as a hyperplane. Additionally, SVM can be used for regression problems.
What is the primary purpose of SVM?
This machine learning tool is applied in many areas, such as handwriting recognition, intrusion detection, face detection, email classification, gene classification, and web page analysis. It is advantageous due to its ability to process both classification and regression on both linear and non-linear data.
3. Latent Dirichlet allocation (LDA)
To map sentences to topics, Latent Dirichlet Allocation (LDA) is used as a topic modeling technique. This technique uses the Dirichlet distribution to find topics for each document model and words for each topic model. Before generating the topic, numerous processes are conducted by LDA, and certain rules and facts must be taken into account.

Assumptions of LDA for Topic Modelling include:
- Documents with similar topics use similar groups of words.
- Latent topics can be found by searching for groups of words that frequently occur together in documents across the corpus.
- Documents are probability distributions over latent topics, meaning certain documents will contain more words about a specific topic.

4. Word Embedding Models
Word Embeddings, also known as Word Vectors, are a numerical vector representation of words and documents that can be used to approximate meaning. This approach allows words that share similar meanings to have similar representations and reduces the dimensionality of words. Each word vector contains values that correspond to features such as age, sports, fitness, and employment status. The goal of Word embedding is to capture inter-word semantics and to use a word to predict the words around it.
Word Embeddings Application
Word Embeddings are used as inputs for Machine Learning models. They take words and give them a numeric representation, which can then be used in training and inference. Additionally, Word Embeddings can be used to visualize any underlying usage patterns in the corpus used to train them.
TransMon Text Analytics can help your business improve your CX.



{kind=link}
{kind=link}
{kind=link}